Brain tumor classification with MRI data
Authors
- Apurva, Lawate
- Rijvi, Kulkarni
Dataset
The dataset used in our experiments is Brain Tumour MRI Dataset
The brain MRI dataset used in this study is a combined collection of three publicly available sources, curated by Masoud Nickparvar (Kaggle) to ensure sufficient diversity and class balance for deep learning–based tumor classification.
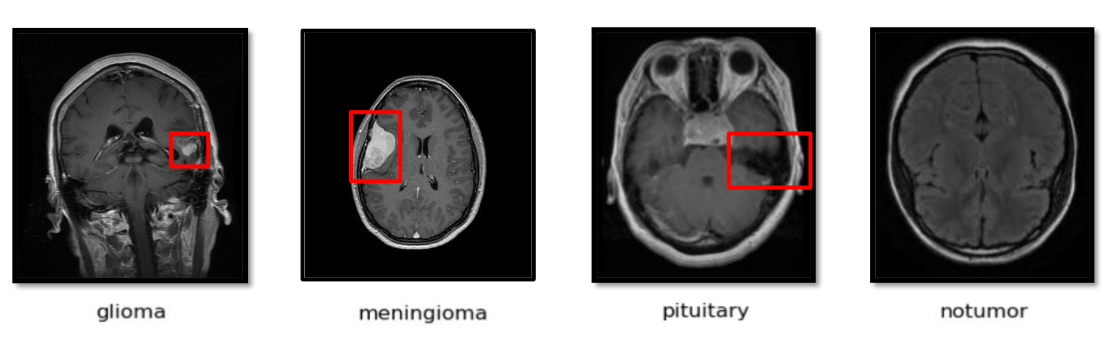
The final dataset comprises 7,023 T1 weighted contrast-enhanced MRI images, each categorized into one of four classes: glioma, meningioma, pituitary tumor, and no tumor.
Figshare Dataset contains 3,064 T1-weighted contrast-enhanced images representing three major brain tumor types. Detailed documentation and acquisition protocols are provided in the accompanying Figshare repository readme file.
Sartaj Dataset is an open-source collection prepared by Sartaj Bhuvaji and team, this dataset supplements the tumor classes with additional MRIscans to improve model robustness and generalization.
Lastly, Images representing the no tumor category weresourced from the Br35Hdataset. These healthy brain scans provide essential negative samples, enabling the model to learn to distinguish normal anatomy from pathological conditions.
By integrating these three complementary datasets, we constructed a comprehensive and well-balanced dataset suitable for training and validating deep learning models aimed at automated brain tumor detection and classification.
Model(s)
Four models are employed in the project:
-
ResNet-50 is a 50-layer deep residual network designed to address the vanishing gradient problem by using skip connections (residual blocks). These connections allow gradients to flow directly through the network, enabling training of very deep architectures. It achieves excellent accuracy on image classification tasks while remaining computationally efficient for its depth.
-
DenseNet-121 introduces dense connections, where each layer receives inputs from all preceding layers. This promotes feature reuse, reduces the number of parameters, and improves gradient flow for more efficient learning. It is well-suited for applications requiring strong feature propagation with a relatively compact model size.
-
MobileNet-V2 is optimized for mobile and embedded devices, using depthwise separable convolutions and inverted residuals. It provides an excellent trade-off between accuracy and speed, making it ideal for resource-constrained environments. The architecture is lightweight, ensuring low latency and minimal memory usage without significant performance loss.
-
VGG-16 is a 16-layer convolutional neural network known for its simple and uniform architecture of stacked 3×3 convolution layers. Although it has more parameters and higher memory requirements than newer models, it remains a strong baseline for image classification. Its straightforward design makes it easy to adapt for transfer learning and feature extraction tasks.
Results
We have the following results:
Model Performance Summary (Quantitative Analysis)
| Model | Epochs | Optimizer | Learning Rate | Precision (%) | Recall (%) | F1-score (%) | Accuracy (%) |
|---|---|---|---|---|---|---|---|
| ResNet-50 | 149 | Adamax | 0.001 | 96 | 96 | 96 | 96 |
| DenseNet-121 | 41 | Adamax | 0.001 | 68 | 70 | 66 | 71 |
| MobileNet-V2 | 77 | Adam | 0.0001 | 96 | 96 | 96 | 96 |
| VGG-16 | 85 | Adam | 0.0001 | 96 | 96 | 96 | 96 |
ResNet-50 is overall best model, however MobileNet-V2 is cheaper, and VGG-16 has advantage in classifying some classes better than other two.
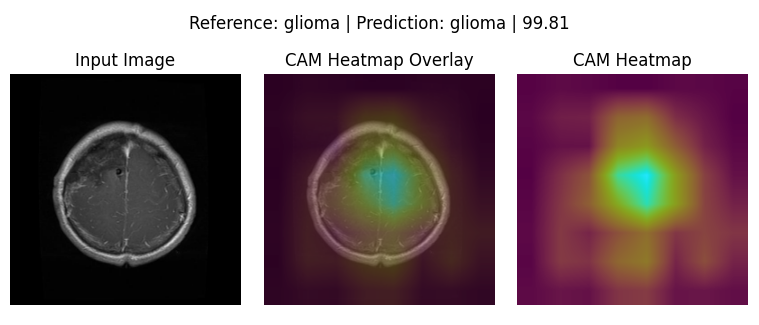
GradCAM (Qualitative Analysis)
The below 4 images are good representation for where the respective models were actually looking to make the Classifications:
ResNet-50:
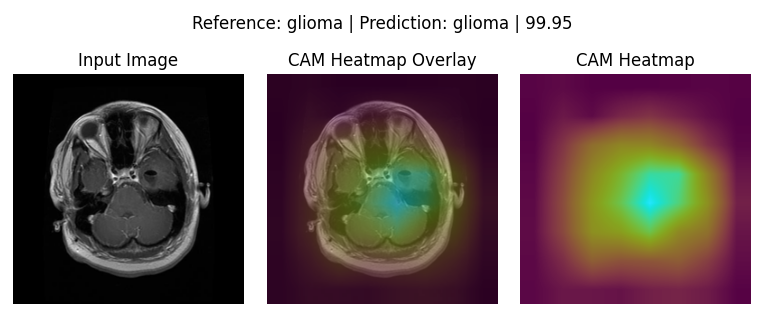
DenseNet-121:
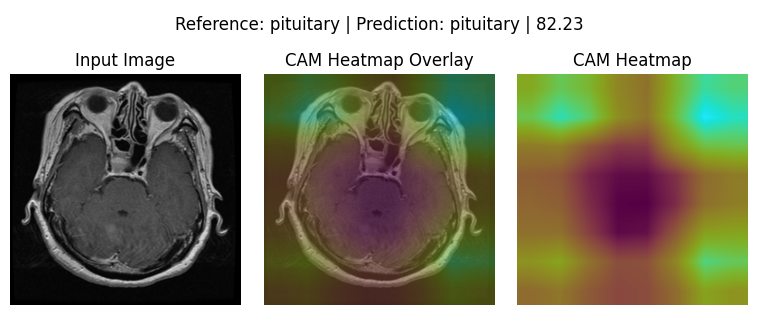
MobileNet-V2:
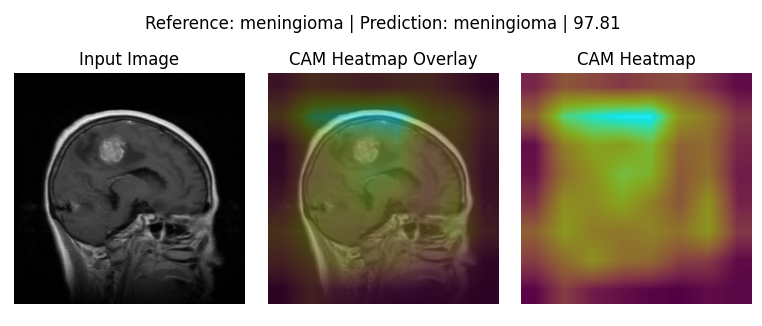
VGG-16: